Daniel
Alves de
Camargo

3+
11
30%
∞
Python
Pandas · NumPy · FastAPI · Selenium
SQL
PostgreSQL · DuckDB
Data Lake / ETL
Parquet · JSON · CSV · LakeHouse
Databricks
LakeFlow · Data Ingestion
APIs
REST · SOAP · FastAPI
JSONata
AI / MCP
Git · Bash
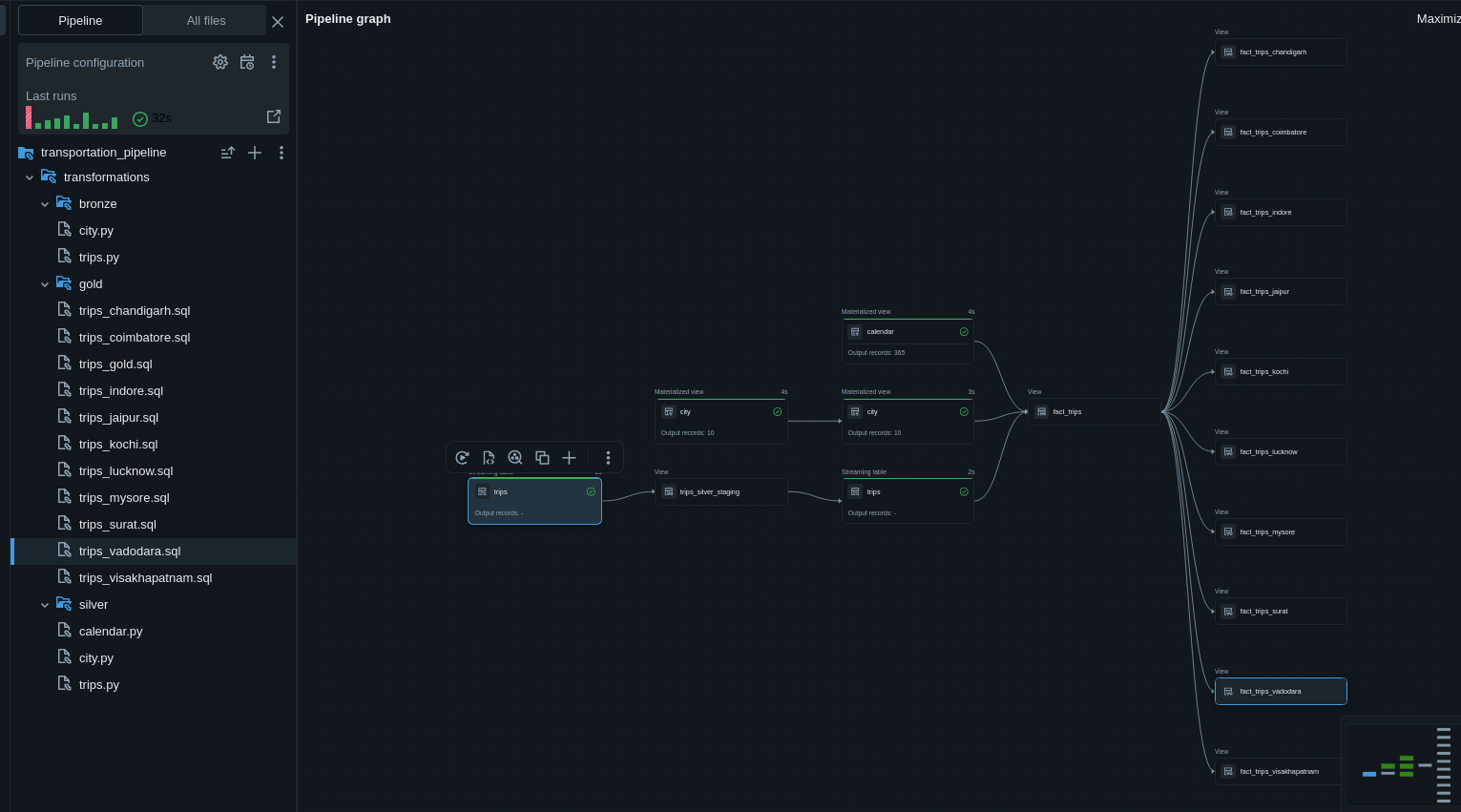
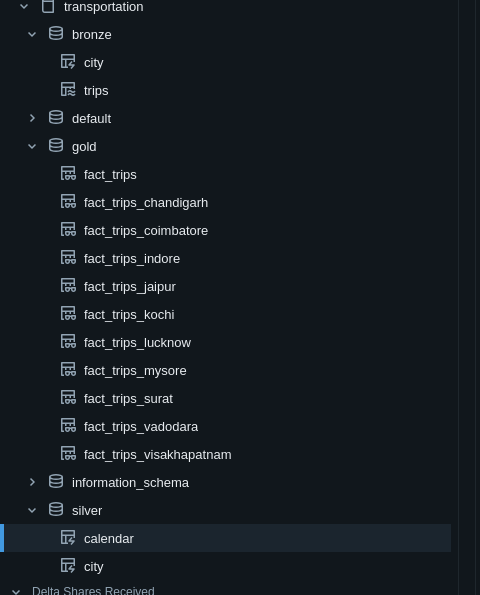
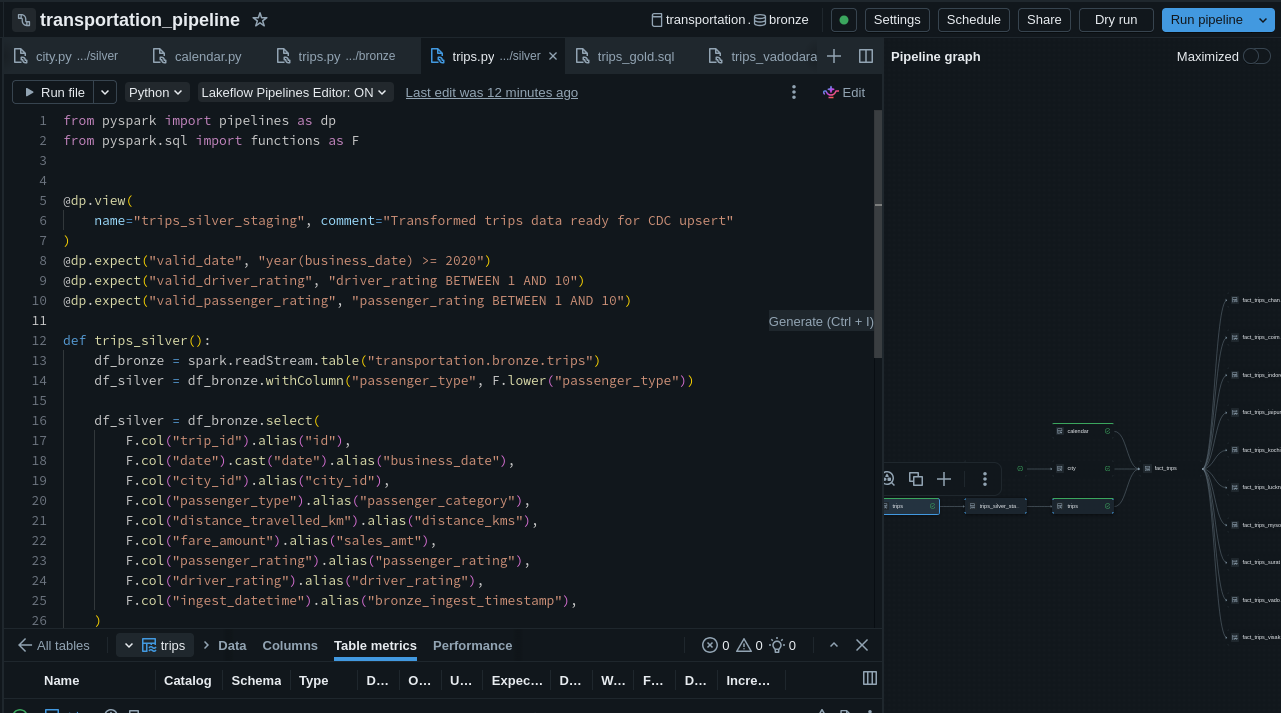
CoinGecko → PostgreSQL Pipeline
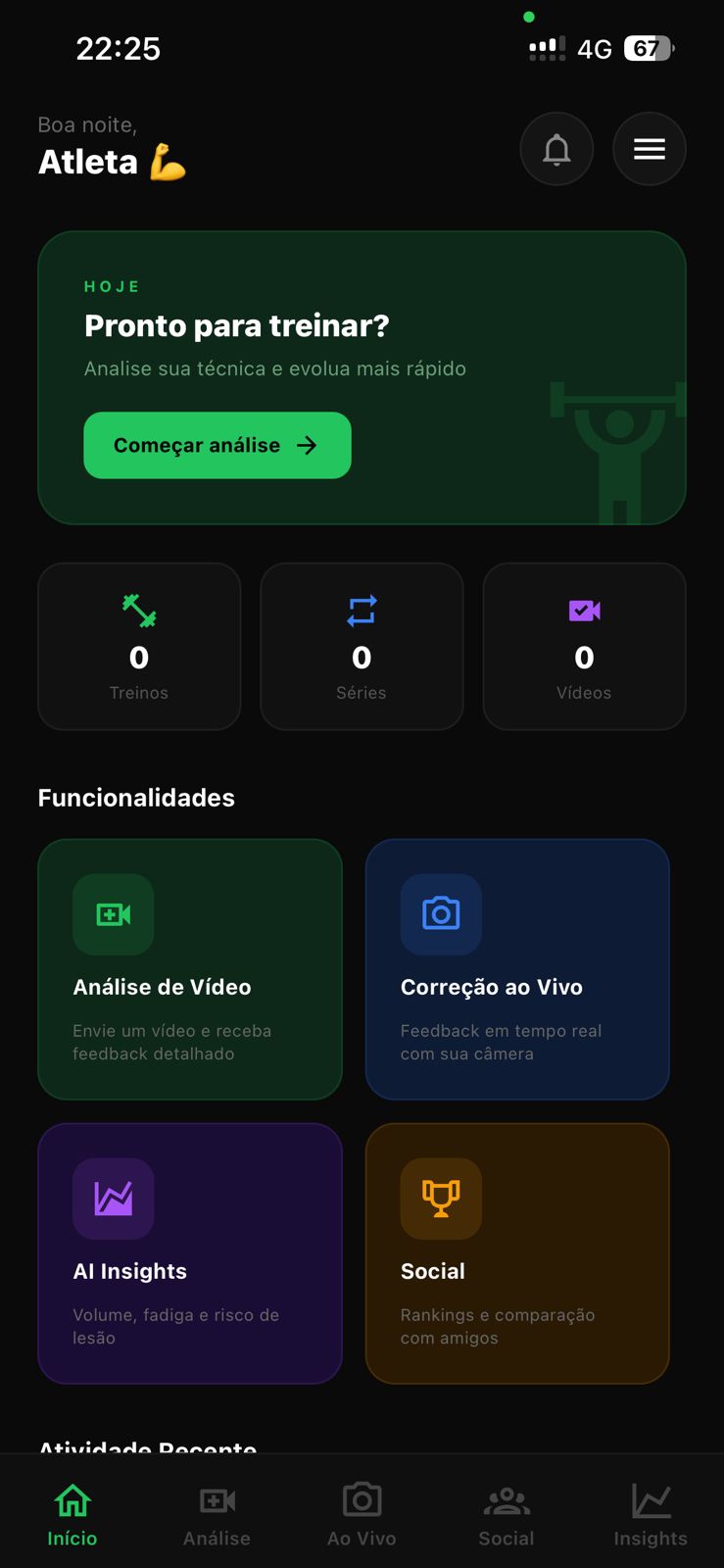
SmartLift.AI